Django Monitoring verstehen: Metrics, Logs, Systemdesign
Viele Django-Anwendungen laufen lange „einfach so“. Requests kommen rein, Daten werden verarbeitet, Antworten gehen raus. Solange nichts offensichtlich kaputt ist, fühlt sich das System stabil an.


Das Problem zeigt sich erst dann, wenn etwas nicht mehr funktioniert. Plötzlich ist die Anwendung langsam, Fehler treten auf oder einzelne Requests dauern ungewöhnlich lange. Ohne Monitoring bleibt in solchen Momenten oft nur Raten. Logs helfen nur begrenzt, weil sie keinen Überblick liefern. Genau hier beginnt Monitoring.
Was ist Monitoring wirklich?
Monitoring bedeutet, den Zustand eines Systems kontinuierlich zu beobachten und messbar zu machen. Dabei geht es nicht nur darum, Fehler zu sehen, sondern zu verstehen, wie sich das System verhält.
Man unterscheidet dabei grob zwei Arten von Daten:
- Metrics, also messbare Werte wie Anzahl von Requests oder Antwortzeiten
- Logs, also konkrete Ereignisse und Fehlermeldungen
Metrics beantworten Fragen wie „Wie viele Requests pro Sekunde verarbeitet das System?“ oder „Wie lange dauern Antworten im Durchschnitt?“. Logs hingegen liefern Kontext, etwa warum ein bestimmter Request fehlgeschlagen ist.
Beides zusammen ergibt ein vollständigeres Bild.
Das System verstehen
Ein gutes Monitoring-System trennt diese beiden Datenarten klar und führt sie an einer Stelle zusammen. Im Django-Kontext sieht das typischerweise so aus:
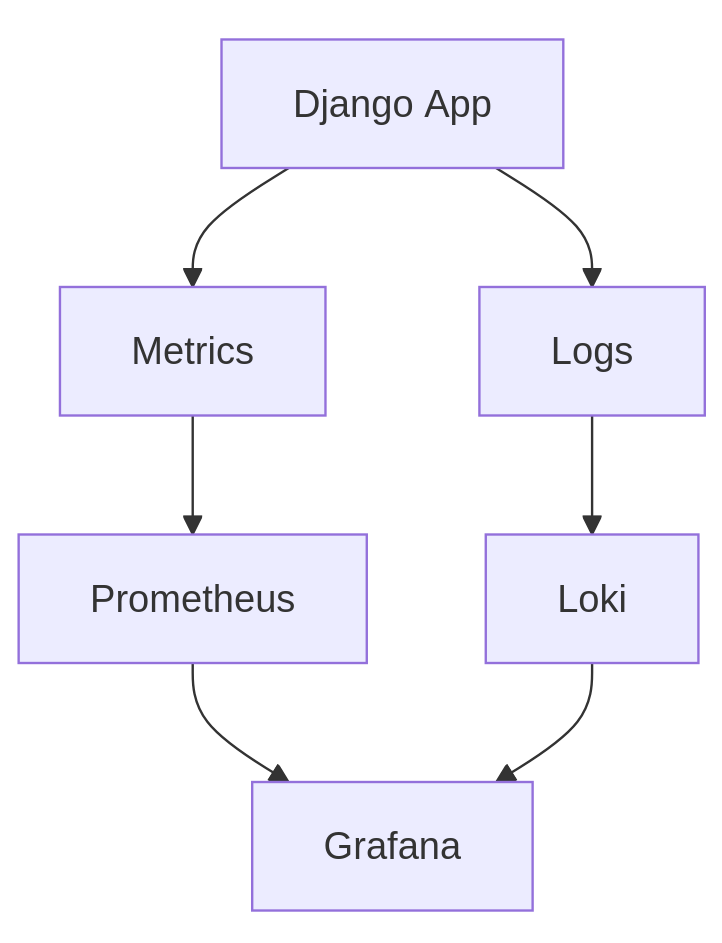
Die Django-Anwendung erzeugt sowohl Metrics als auch Logs. Metrics werden von Prometheus gesammelt, während Logs über ein System wie Loki verarbeitet werden. Beide Datenströme laufen schließlich in Grafana zusammen, wo sie visualisiert werden.
Wichtig ist hier nicht das konkrete Tool, sondern die Struktur. Metrics und Logs werden getrennt verarbeitet, aber gemeinsam ausgewertet.
Metrics verstehen
Metrics sind aggregierte, numerische Daten. Sie helfen dabei, das Verhalten eines Systems über Zeit zu verstehen.
Typische Beispiele in einer Django-Anwendung sind:
- Anzahl der Requests pro Sekunde
- durchschnittliche Antwortzeit
- Fehlerquote (z. B. HTTP 500)
Diese Werte ermöglichen es, Trends zu erkennen. Man sieht, ob die Last steigt, ob bestimmte Endpunkte langsamer werden oder ob Fehler häufiger auftreten.
Der große Vorteil von Metrics ist ihre Effizienz. Sie lassen sich sehr schnell erfassen und auswerten. Dadurch eignen sie sich besonders gut für Dashboards und Alerts.
Logs verstehen
Logs sind detaillierter und konkreter. Sie enthalten Informationen über einzelne Ereignisse, etwa einen fehlgeschlagenen Request oder eine Exception.
Ein typischer Log-Eintrag könnte enthalten:
- Zeitpunkt
- betroffener Endpoint
- Fehlermeldung
- Kontextdaten
Logs sind unverzichtbar, wenn es darum geht, Probleme im Detail zu analysieren. Während Metrics zeigen, dass etwas schiefläuft, erklären Logs, warum das passiert.
Der Nachteil ist, dass Logs schwerer auszuwerten sind. Sie sind unstrukturiert und oft sehr umfangreich. Deshalb braucht man spezialisierte Systeme, um sie sinnvoll zu durchsuchen.
Zusammenspiel von Metrics und Logs
Der eigentliche Mehrwert entsteht erst durch das Zusammenspiel beider Datenquellen.
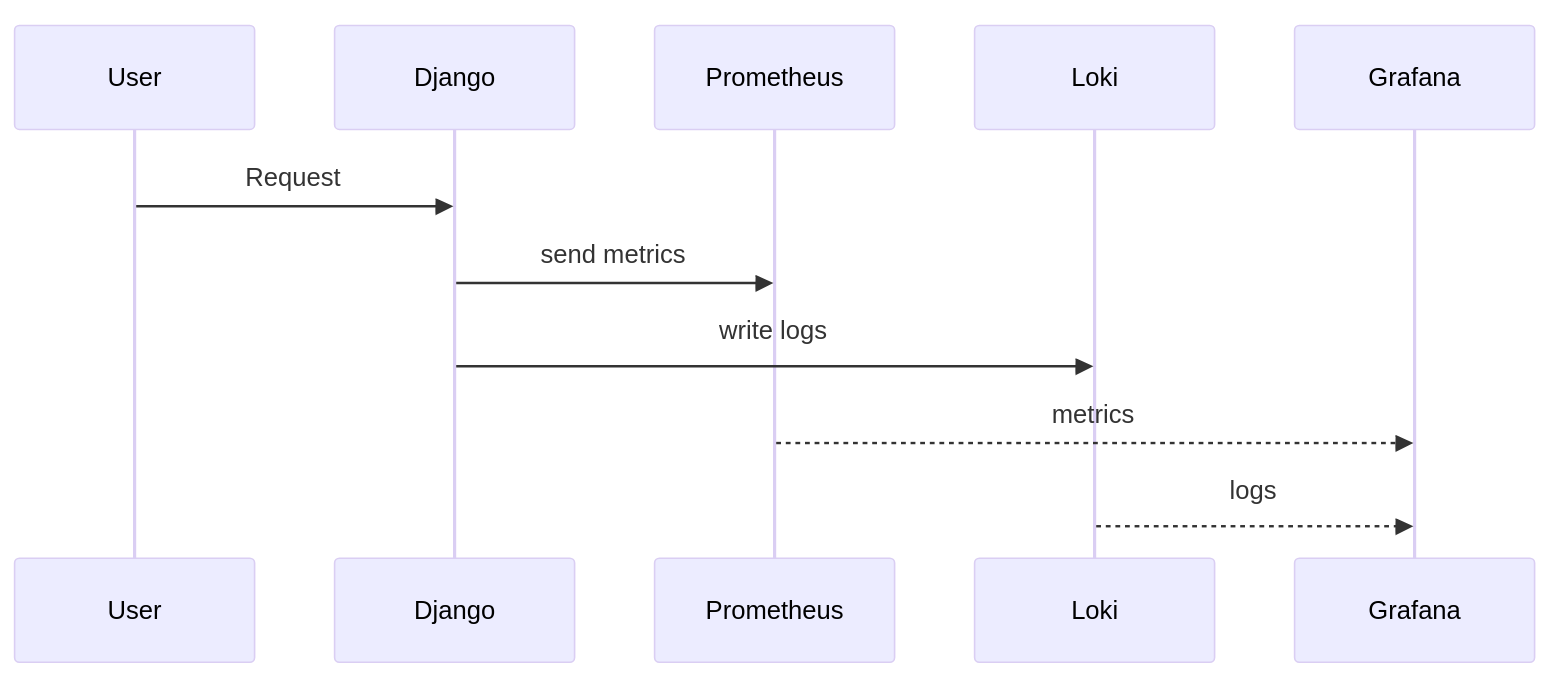
Ein Request trifft auf die Django-Anwendung. Während der Verarbeitung werden sowohl Metrics erzeugt als auch Logs geschrieben. Diese Daten werden parallel gesammelt und später gemeinsam analysiert.
In Grafana kann man dann beispielsweise sehen, dass die Antwortzeiten steigen und gleichzeitig die passenden Logs dazu aufrufen. Erst diese Kombination ermöglicht eine fundierte Analyse.
Wie sieht das in der Praxis aus?
An dieser Stelle lohnt sich ein Blick auf ein reales Dashboard.
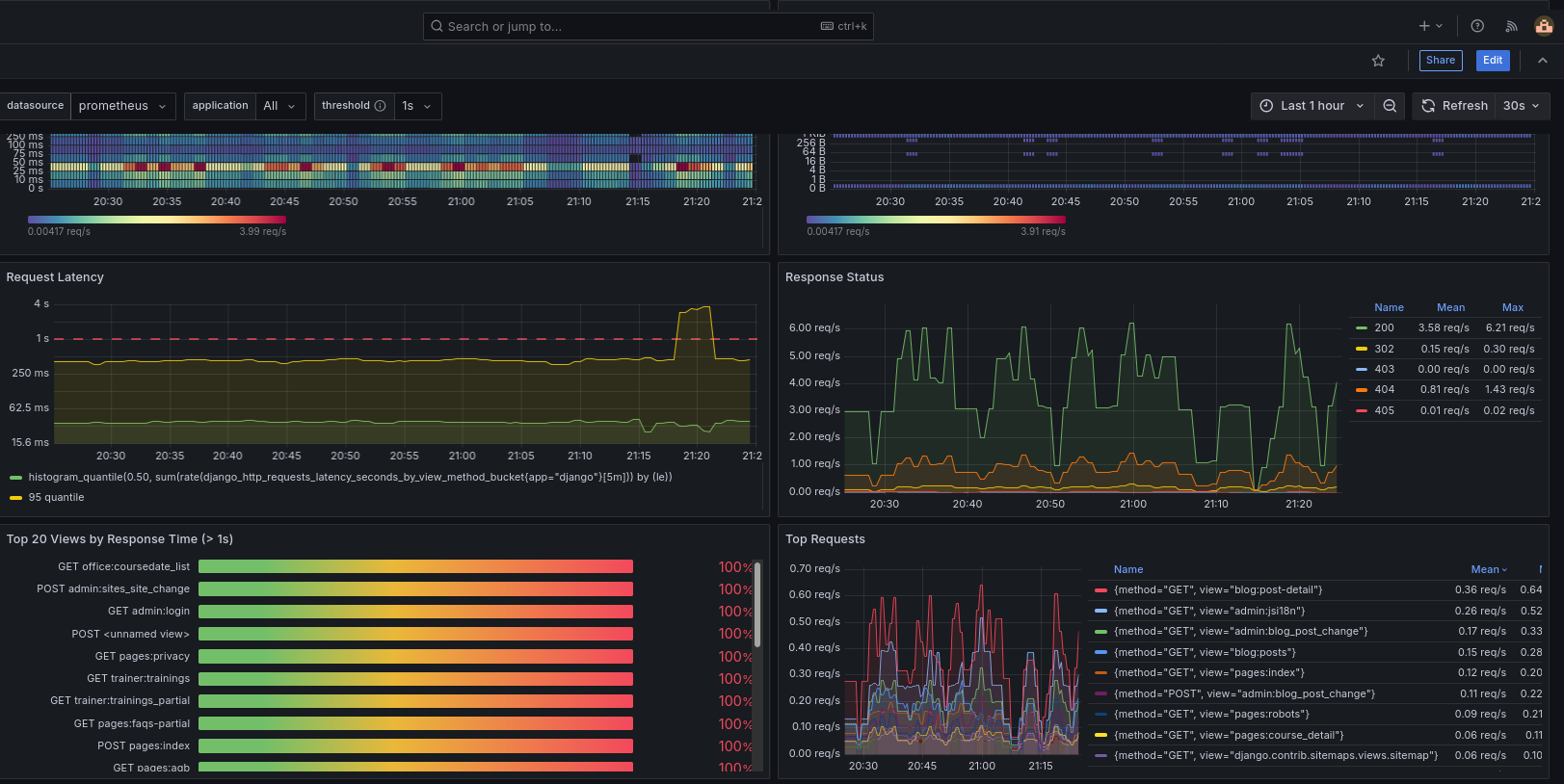
Ein typisches Grafana-Dashboard zeigt:
- Request-Raten über Zeit
- Antwortzeiten einzelner Endpunkte
- Fehlerquoten
- eventuell Systemmetriken wie CPU oder Speicher
Der entscheidende Punkt ist nicht das einzelne Diagramm, sondern die Gesamtsicht. Man erkennt Muster, Zusammenhänge und Veränderungen im System.
Warum Monitoring Teil des Systemdesigns ist
Monitoring wird oft als nachträgliches Feature betrachtet. Erst wenn Probleme auftreten, beginnt man darüber nachzudenken.
Das ist ein Fehler.
Monitoring ist ein integraler Bestandteil des Systemdesigns. Es bestimmt, ob ein System überhaupt beobachtbar ist. Ohne diese Beobachtbarkeit lassen sich weder Performance-Probleme noch Fehler zuverlässig analysieren.
Ein gut designtes System stellt sicher, dass:
- relevante Metrics vorhanden sind
- Logs strukturiert und zugänglich sind
- Daten zentral ausgewertet werden können
Bezug zur Django-Architektur
Monitoring hängt eng mit der Struktur der Anwendung zusammen. Wenn Logik unklar verteilt ist, wird auch Monitoring schwierig.
Ein sauber strukturierter Service Layer hilft beispielsweise dabei, gezielt Metrics zu erfassen und Logs an sinnvollen Stellen zu schreiben:
👉 Services in Django – saubere Trennung von Logik
Gleichzeitig zeigt sich, dass viele Probleme überhaupt erst durch fehlende Struktur entstehen:
👉 Warum 90 % aller Django-Projekte unwartbar werden
Und wie eine saubere Gesamtstruktur aussieht, wird hier im Detail erklärt:
👉 Wie ein wartbares Django-Projekt aufgebaut ist
Fazit
Django-Anwendungen sind nicht nur Code, sondern Systeme. Diese Systeme müssen beobachtbar sein, um langfristig stabil zu bleiben.
Metrics zeigen, wie sich ein System verhält. Logs erklären, warum es sich so verhält. Erst zusammen ermöglichen sie ein echtes Verständnis.
Die Aufgabe des Entwicklers hat sich damit verändert. Es reicht nicht mehr, Features zu implementieren. Es geht darum, Systeme zu entwerfen, die skalierbar, wartbar und nachvollziehbar sind.
Monitoring ist dabei kein optionales Extra, sondern ein zentraler Bestandteil dieser Architektur.

Bernd Fischer
Django & Python Trainer
Django & Python Trainer
Ich helfe Entwicklern, wartbare Python- und Django-Projekte zu bauen.


Kostenloses E-Book: Wartbare Django Projekte, Architektur und Best Practices
Viele Django-Projekte starten sauber und werden mit der Zeit schwer wartbar. Dieses kompakte E-Book zeigt, warum das passiert und wie Django-Projekte strukturiert sein müssen, um langfristig stabil und erweiterbar zu bleiben.
Zum kostenlosen E-Book →
Buchempfehlungen: Django

Django by Example
Ein praktischer Einstieg in Django – mit realistischen Projektbeispielen zur Entwicklung moderner Webanwendungen.

Ultimate Django
Ein umfassender Leitfaden für moderne Django-Entwicklung – ideal für alle, die robuste und skalierbare Webprojekte umsetzen wollen.
* Dies ist ein Affiliate-Link. Wenn du über diesen Link einkaufst, erhalte ich eine kleine Provision – für dich entstehen keine zusätzlichen Kosten.
Buchempfehlungen: System Monitoring

Getting Started with Grafana: Real-Time Dashboards for IT
Real-Time Dashboards for IT and Business Operations (English Edition)

* Dies ist ein Affiliate-Link. Wenn du über diesen Link einkaufst, erhalte ich eine kleine Provision – für dich entstehen keine zusätzlichen Kosten.
Online- und Präsenzkurse zum Thema
Finden Sie interessante und zum Thema passende Kurse
Django Intensiv Schulung
Lernen Sie Django in nur 5 Tagen mit diesem umfassenden Intensivkurs! Vom Einstieg in die Entwicklung Ihrer ersten Webanwendung bis hin zu fortgeschrittenen Themen wie API-Entwicklung und Testing – dieser Kurs deckt alles ab. Perfekt für Entwickler, die schnell produktiv mit Django arbeiten möchten.
5 Tage Vollzeit Online
-
Nächster Termin: 27. Juli 2026
- Preis p.P.: 1600,00 EUR (inkl. MwSt. 1904,0 EUR)
Prompting, Fine-Tuning, RAG, Agenten
Nutzen Sie das Potenzial von KI gezielt für Ihr Unternehmen. In dieser 3-tägigen Python-Schulung lernen Sie, wie Sie Large Language Models praxisnah einsetzen, von Prompting über Fine-Tuning bis zu RAG und Agenten-Workflows. Klare Codebeispiele und viele Übungen sorgen dafür, dass Sie das Gelernte direkt anwenden und fundierte Entscheidungen für den KI-Einsatz treffen können.
3 Tage Vollzeit Online
-
Nächster Termin: 27. Juli 2026
- Preis p.P.: 1400,00 EUR (inkl. MwSt. 1666,0 EUR)
Django Framework für Fortgeschrittene
Entdecken Sie die fortgeschrittenen Funktionen von Django in unserem intensiven Aufbaukurs. Dieser Kurs richtet sich an Entwickler, die bereits mit den Grundlagen von Django vertraut sind und ihre Fähigkeiten auf das nächste Level bringen möchten.
5 Tage Vollzeit Online
-
Nächster Termin: 27. Juli 2026
- Preis p.P.: 1900,00 EUR (inkl. MwSt. 2261,0 EUR)
Unsicher, welcher Kurs für Sie passt?
Gerne unterstütze ich Sie bei der Auswahl oder stelle eine individuell passende Schulung für Ihre Anforderungen zusammen.